1.介绍
约束条件与数据类型的宽度一样,都是可选参数
它们的作用在于保证数据的完整性和一致性
1.1not null 与 deafult
null表示空,非字符串
deafult代表默认值
创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值
create table tb1( id int not null default 2, num int not null );
效果

验证1:
id字段默认为空
create table t11(id int);
desc t11;
效果

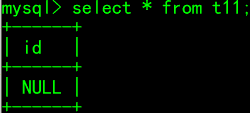
给t11插入一个空值
insert into t11 values(); select * from t11;
效果
验证2
# 设置id字段不为空 create table t12(id int not null); insert into t12 values(); #插入空值,此时显示Field 'id' doesn't have a default value
效果

验证3
设置id字段有默认值(deafult)后,则无论id字段是null还是not null,都可以插入空,插入空默认填入default指定的默认值
create table t13(id int default 1); insert into t13 values(); insert into t13 values(8); insert into t13 values(9); select * from t13;
效果

练习:
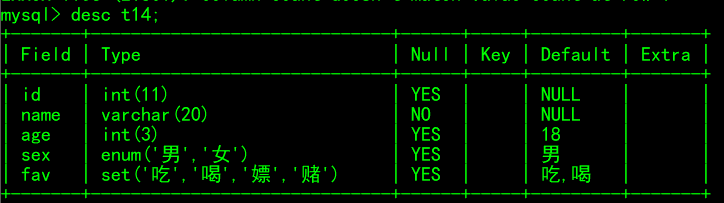
create table t14( id int, name varchar(20) not null, age int(3) default 18, sex enum('男','女') default '男', fav set('吃','喝','嫖','赌') default '吃,喝' ); insert into t14(name) values('乔治'); insert into t14 values(3,'梅子',18,'女','嫖'); insert into t14 values(5,'碧落',22,'男','吃,喝,嫖,赌'); select * from t114;
此时表格结构
效果

1.2唯一性(unique)约束
# 单例唯一
# 即不可重复 create table tab2(id int unique, name char(10) ); insert into tab2 values(1,'first'); insert into tab2 values(1,'second'); # 设置了唯一性约束,此时再插入id= 1,报错 # 也可以分开写 create table tab2(id int, unique(id), name char(10) );
# 多例唯一
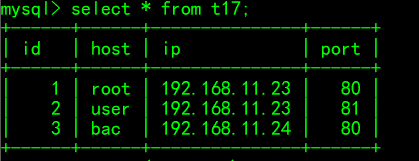
# 联合唯一 create table t17( id int, host varchar(50), ip varchar(50), port int, unique(id), unique(ip,port) # 这两个参数不能同时出现两次,它两组合起来是唯一的 ); insert into t17 values (1,'root','192.168.11.23',80), (2,'user','192.168.11.23',81), (3,'bac','192.168.11.24',80);
结构

效果
2.primary key(主键约束)
约束:primary key等价于not null unique,字段的值不为空且唯一
对于innodb存储引擎,一张表必须有一个主键
create table t19( id int primary key, # 或id int not null unique, name char(16) ); insert into t19 values (1,'luffy'), (2,'zoro'); insert into t19 values(1,'ronan'); # 此时会提示出错

多列做主键,也叫复合主键,和多例唯一性质等同
create table t21( id int, port int, primary key(id,port) ); insert into t21 values (1,80), (1,81);
3.auto_increment(自增约束)
约束:约束的字段为自动增长,约束的字段必须同时被key约束
create table t22( id int primary key auto_increment, name varchar(50), sex enum('male','female') default 'male' ); insert into t22(name) values ('依违'),('杜瓦'); insert into t22 values(4,'乔伊','female');
效果
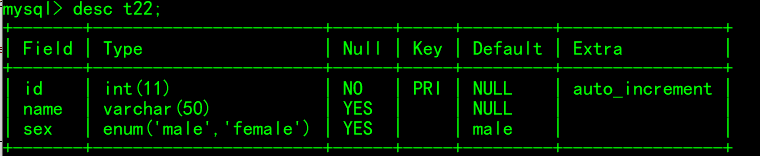
结果

现在在穿插一个id为3的数据
insert into t22 values(3,'乔','male');
效果,id居然按顺序排列了
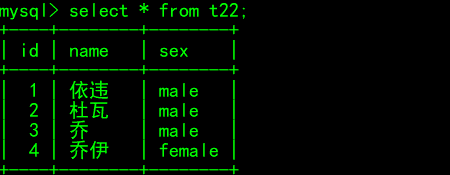
## 对于自增的字段,再用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
delete与truncate的区别
delete:如果有自增id,新增的数据,仍然是以删除前的最后一行作为起始
truncate:数据量大,删除速度比上一条快,且直接从零开始
4.foreign key(外键约束)
某个字段大量重复存储时才使用,方便存储,而且节省内存
至少存在两张表,一张从表(关联表),一张主表(被关联表)
如部门样式表(假设部门有员工1000人)
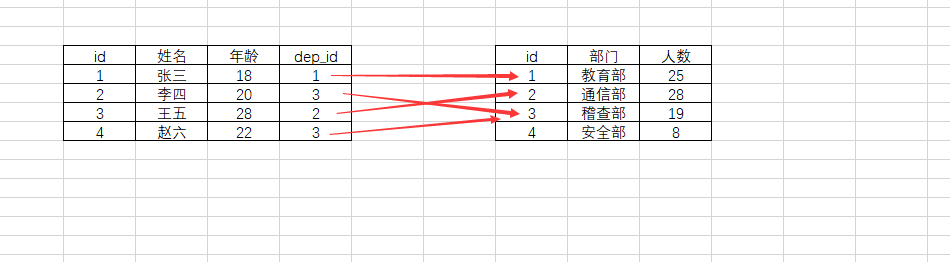
多对一:一个表多条记录的某一字段关联另一张表的唯一一个字段(如id)
(先建被关联的表,被关联的表必须唯一,先给被关联的表插入记录)
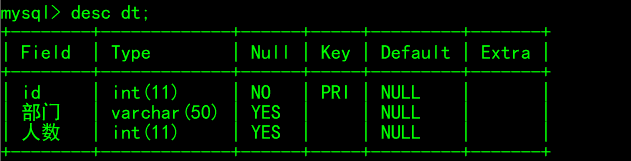
# 被关联表 create table dt( id int not null unique, 部门 varchar (50), 人数 int ); # 关联表 create table mes( id int primary key auto_increment, 姓名 varchar(50) not null, 年龄 int not null, d_id int, constraint main_id foreign key(d_id) references dt(id) on delete cascade # 同步删除 on update cascade # 同步更新 ); # 从表插入记录 insert into dt values (1,'教育部',25), (2,'通信部',28), (3,'稽查部',19), (4,'安全部',8); # 主表插入记录 insert into mes values (1,'张三',18,1), (2,'李四',20,3), (3,'王五',28,2), (4,'赵六',22,3); # 插入记录 insert into mes(姓名,年龄,d_id) values('棱七',88,4); # 更改id update dt set id=666 where id=3;
被关联表dt结构
关联表mes结构
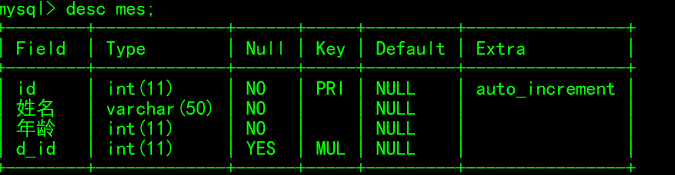
插入数据的被关联表dt

插入数据的关联表mes
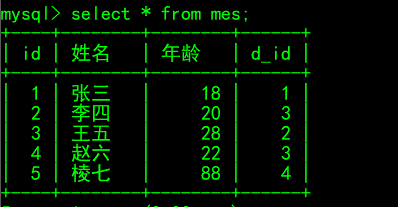
更改数据后的被关联表dt

更改数据后的关联表mes

总结:这里一定要在关联表中插入下面两句话,这两句话实现了数据的实时同步,不用我们挨个表格去更改数据
on delete cascade #同步删除
on update cascade #同步更新
4.1外键之间的关联
表与表之间的对应关系不单单有多对一,还包括多对多,一对一的形式
## 多对一,比如书和出版社之间,一个出版社可以出版多种书,这就是多对一的形式
这里被关联表就是出版社,关联表就是多本书

代码


# 被关联 create table mained( id int not null unique auto_increment, name varchar(50) ); # 关联表 create table main( book_id int not null unique auto_increment, book_name varchar(50), book_price int(3) zerofill, press_id int not null, constraint con_id foreign key(press_id) references mained(id) on delete cascade on update cascade ); # 从表插入记录 insert into mained(name) values ('新华出版社'), ('百度出版社'), ('大众出版社'); # 主表插入记录 insert into main(book_name,book_price,press_id) values ('Python爬虫',100,1), ('操作系统应用',20,1), ('C语言设计',50,2), ('英语',30,3), ('语文',70,3);
## 一对一,比如学生表和客户表之间,一个学生对应一个客户
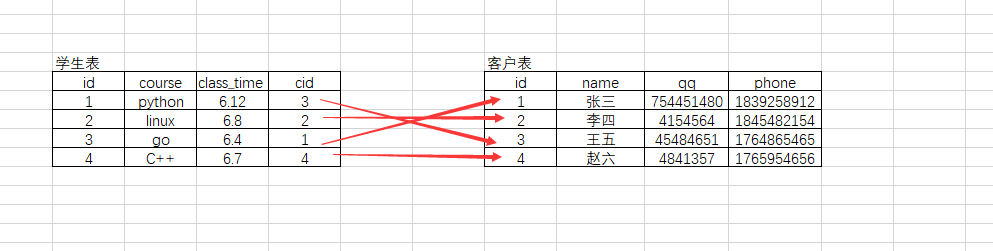
代码
# 被关联表 create table iu( id int not null unique auto_increment, name varchar(50), qq int unique, phone int unique ); # 关联表 create table dbui( id int not null unique auto_increment, course varchar(50), class_time time, cid int unique, foreign key(cid) references iu(id) on delete cascade on update cascade ); # 被关联表数据 insert into iu(name,qq,phone) values ('张三',754451480,1839258912), ('李四',4154565,1845482154), ('王五',45484651,1764865465), ('赵六',4841357,1765954656); # 关联表数据 insert into dbui(course,class_time,cid) values ('python',now(),3), ('linux',now(),2), ('go','06:13:00',1), ('C++','06:13:00',4);
## 多对多,一个作者可以写多本书,一本书也可以有多个作者,双向的一对多
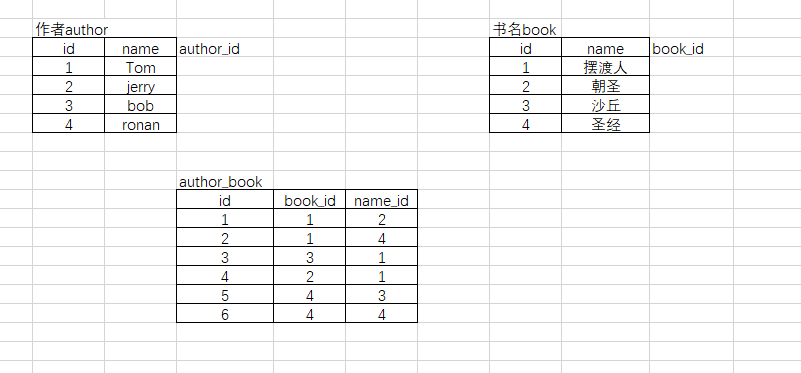
代码
# 多对多 create table author( id int not null unique auto_increment, name varchar(50) ); create table books( id int not null unique auto_increment, name varchar(50) ); create table author_books( id int not null unique auto_increment, book_id int not null, name_id int not null, foreign key(book_id) references books(id) on delete cascade on update cascade, foreign key(name_id) references author(id) on delete cascade on update cascade, primary key(book_id,name_id) ); # 加入数据 insert into author(name) values('Tom'),('jerry'),('bob'),('ronan'); insert into books(name) values('摆渡人'),('朝圣'),('沙丘'),('圣经'); insert into author_books(book_id,name_id) values(1,2),(1,4),(3,1),(2,1),(4,3),(4,4);
## 要注意,1.先建被关联的表,保证被关联的字段必须唯一
2.在创建关联表,关联字段一定要是有重复的
外键关联方式语句:
foreign key(关联表id) references(被关联表id)
on delete cascade
on update casdate